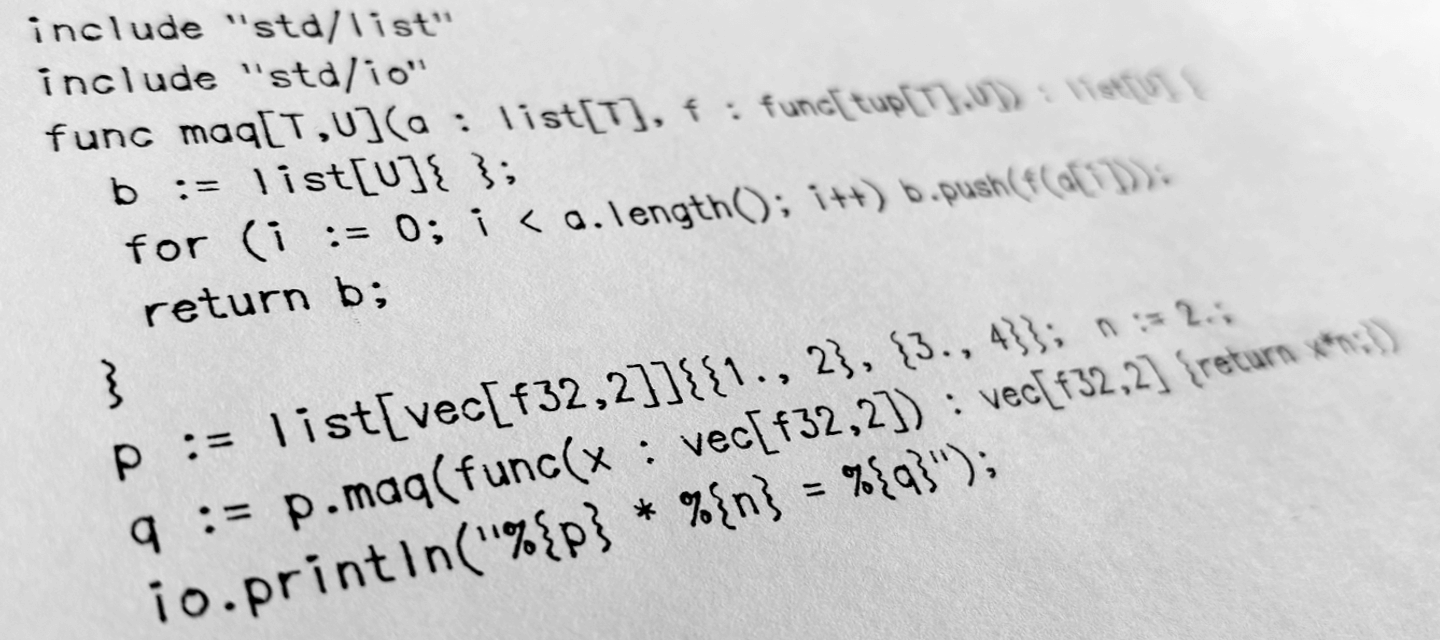
The Design of Dither
This document discusses the design decisions of the Dither programming language: why things are the way they are, and some (very) subjective opinions of the author. While you can certainly learn some Dither through reading this, it'd be more effective to consult the syntax guide or other tutorials in this series, if your goal is to learn the language.
Overview
The design of Dither is centered around a few core ideas:
Compact
There're pedantic, verbose programming languages that leaves no trace of ambiguity, there're very succinct programming languages that verges on becoming esoteric. Dither doesn't deliberately try to be either — it instead is centered around the idea that every word (or token) should do something the programmer wants. There should be as little boilerplate or semi-useless conceptual abstract fluff as possible, and every bit of code does something and it is apparent what it does; but there's also no need to be short for the sake of being short. Perhaps this style can be described as compact or “effect-oriented”.
Symbols are Visual Anchors
Code is meant to be read (at least once when it is written). When you have too many different symbols ($%*?...) and the words are too short, your code starts to resemble line noise; When you are too thrifty with the kinds of symbols and have words that are too long, one gets lost in the repetition. Achieving a balance so that at a glance, one gets a rough idea of what is, or could be, happening in the code is one of the more important reasons that dictates what spelling of keywords and selection of symbols are picked for Dither. The symbols should create a visual anchor for the programmers' eyes to “latch” onto.
Vectors-First
Dither is a language for creative coding, which often involves dealing with numbers. Dither believes that vectors (and matrices) are just a bunch of numbers, and anything that works with numbers should also automatically work with vectors. This idea is in no way new in scientific programming languages, but is sometimes lacking by default in generic languages, which Dither aims to rectify.
No Self-Inflicted Handicaps
Many modern programming languages insist on helping programmers write the correct program. They prevent things that might be problematic from being written at all, and implement such measures that a large team with differing skill levels can collaborate and nothing too crazy happens. Dither is not such a language — it is less enthusiastic about things that hinders people, then things that enables people. It relies on the programmers' good habits and conventions to use the language effectively and correctly.
Keeping Things Simple
Sometimes the language designer is presented with two choices: One which introduces new constructs that are in theory “better” or more efficient for the computer, the other builds on basic things which the programmer is already familiar with (but might be slightly less efficient). The Dither standard library faces many such choices and always picks the latter when not at a critical bottleneck in performance.
A Nice, Boring Language
While Dither has a few somewhat exciting and somewhat unique syntactic features, they're there because they're useful, and not because Dither aims to have an exciting and unique syntax. We believe it is better to have a familiar and generic syntax so the programmer can better allocate their time to writing the actual thing they want, rather than spending it on learning the language itself. That said, Dither does incorporate all the nice things you can expect in a sleek, modern language into the syntax: type inference, polymorphism, functional programming, etc.
Now let's get into the actual design choices of the language.
Variables
Variables can be declared and assigned to, and how to discern these two scenarios (and if it is necessary at all to discern) presents an interesting question. Some languages have a special keyword for declaring a variable (e.g. var or let). The older, statically typed languages get to “cheat” a little bit by putting the type before the variable name to mean declaration (e.g. int x = 3 v.s. assignment x = 3). When type inference is introduced, the type gets replaced by a special keyword again (var/auto x = 3, etc.). Modern languages tend to prefer putting the type after the variable name. While this is more natural when type is just an annotation and can be inferred, it may require both the special keyword (var) and the type on either side of the name when the type is explicit.
Some languages use the same syntax for declaration and assignment. While it can seem very convenient at first, it presents more headaches as soon as the program gets slightly more complicated. The designer of these languages must have been like “why do we even need to have different things for that, let's just make them the same and it'll be convenient!” but later when they realize that it becomes ambiguous whether one is declaring a new local variable or assigning to an older one in the parent scope, they're like “Oh snap, let's put a bandage on that” and go on to invent keywords like global and nonlocal.
Another question is whether there should be a separator or symbol between the variable name and type. Many modern languages seems to have reached the consensus that : is the best symbol for that. The older languages which has type up front just use whitespace as separator, and some modern languages, while reversing the order of type and name, stick to not having a special symbol.
Dither is designed to have type inference, so putting name before type is the more natural choice. While leaving out the : separator indeed saves a keystroke and makes little difference to the parser, having it give the code more visual clues to latch onto, so at a glance it is easier to have a rough idea of what's happening.
Having no extra keyword for declaration is somewhat tempting, but not being able to tell between declaration and assignment is terrible. Dither pulls together all these concerns and discovers an elegant trick. When a variable is declared with an explicit type, one writes x : i32 = 0. This discerns it from assignment, which requires no types (x = 0), without an extra keyword. When a variable is declared but the type is to be inferred (which constitutes most situations), one simply omits the type itself and writes x : = 0, and here comes the cool part: you can also omit the space between : and the =, making it x := 0, where := is also known as the “walrus operator”. So for the average user, they only need to remember “use := for declaration, use = for assignment”, while the syntax logically makes sense and the parser doesn't even know about := and doesn't need to do anything extra at all. This is some else if level of elegance (more on that later).
When there's no initial value but there is a type, one simply writes x : i32. When there's neither initial value nor type, well, you just can't have that (not in any typed language), because then who knows what you're declaring?
Types
Let's start with the built-in numerical types: ints and floats, signed and unsigned. First of all, whether or not they should all exist. Indeed, some languages just store all numbers as floating-points, which can represent integers up to a certain range depending on the width of the float. Some languages lack certain integer widths or signs. Dither, being a legit language, decides to have all the widths and signs supported (up to 64 bits). When you think about it, each numerical type has valid use cases where they have a strong reason to exist (yes, even the 16-bits). And it is better to have them, than leave it to the programmer to come up with some hacks.
Next, traditionally in programming languages, there're these mnemonic names for the numerical types, such as unsigned short for uint16, or double for the 64-bit float, etc. But there're a few complications. Firstly, in some languages, a name like this doesn't always correspond to a single width. For example, an int only needs to be wider than 16 bits. In these languages, an int is more meant to be “the natural integer size on the system” then is to correspond to a fixed size. That is reasonable, but nowadays having something definite and standardized seems more preferable. Secondly, these names don't help that much anyways: Double? double of what? Double precision floating point number? what's floating point number? You see, unless the programmer already have a decent understanding of presentation of numbers on computers, the names are just superficially friendly. Finally, it pollutes the global namespace with all these random funny words “char”, “short”, “long long” that seems all over the place without some sort of pattern or organization.
Many modern languages now resort to simply stating the width explicitly in the type name, leaving no room for wild imagination. But a choice is still present: whether to spell things out, e.g. integer64 or int64, or simply have the abbreviation i64? Dither went with the compact route, as i64 is sufficiently common and clear that the extra keystrokes don't feel necessary. As type annotations are very common in function declaration argument list, being able to fit more in a single line without making a mess also helps.
One might argue: a beginner must wonder, what the heck does f32 mean? Well, if they're truly a beginner, they wouldn't know what a float means either, so it takes equal amount of explanation to let them know what f32 means. If they're not truly a beginner and in fact came from another language which uses float, then they should already at least have heard of floating point representation and it wouldn't take much explanation to let them know the exact same thing is called f32 here.
One final decision remains: whether or not to capitalize the first letter of the type name. There're programming languages in either camps. One can argue that types should look a bit different from variables and therefore should all be title-cased. Dither picked all-lowercase mostly for aesthetical reasons. Capital letters sprinkled around is both tiresome for the fingers and for the eyes, since the “skyline” made out of characters would jump up and down. It also gives off an air of being formal and pedantic. (In standard library, snake_case is also used in favor of camelCase for a similar reason).
Users can give their custom data types (classes, structs, or whatever you call it) title-case names, if it suits their style or the convention of their group. This way, capitalization will distinguish built-in types and custom types, which isn't a bad thing either.
In addition to numerical types (i8,u8,i16,u16,i32,u32,i64,u64,f32,f64), Dither also provide other built-in types such as str, vec, tup, list, arr, dict, etc. There was initially the plan to make every built-in type exactly 3 letters for the purpose of alignment, but in the end it was deemed too cultic and would introduce some awkward looking abbreviations. Nevertheless, short names and well-accepted abbreviations are used to keep these names generally under 4 letters, and OCD patients like myself would have to resort to whitespace for alignment.
Compound Types
For “compound”/“container” types, Dither picks the square brackets [] for the type constructor, as opposed to the more widely-used angular brackets <>, e.g. dict[str,i32], list[tup[i32,f32]] etc. This is more consistent as the square brackets are already used thusly for parameterization outside of type annotations (templates, subscripts, decorators, etc.), and it doesn't feel too necessary to introduce a new set of brackets just for types. It also simplifies parsing for the compiler, as < and > are used for less and greater than too, and to overload them the parser needs to switch context (parsing a type right now or not?), whereas if square brackets are globally used to create parameters, things get parsed a bit more elegantly. Also, angular brackets look stabby!
What container types to include as built-in is also an interesting question. There're some minimalist languages that says everything is a “table”. You can use it as a list, you can use it as a map, just shove stuff in any way you want. Some less radical languages distinguishes between a list and a map, but that's all you get. Some doesn't give you anything at all and you have to write them yourself from a heap of memory. Some gives you a whole suite of every container you'll ever need (but probably as standard library).
Dither finalized on the current set of containers after some back and forth. “vec”, vectors in mathematical sense, are of course necessary because of Dither's approach to first-class vector and matrix math. Matrices are simply 2nd order vectors (tensors are simply even higher order vectors), so they're all encapsulated in the same type vec, with the name being picked (in favor of mat or ten for example) as the 1st order ones are the most common and recognized. To specify a vector, one gives the element type and number of elements as parameters, e.g. vec[f32,3] is a 3D vector. For matrices, the rows and columns are specified, e.g. vec[f32,4,4] is a 4x4 matrix, and the parameter count increases for each tensor order incremented. More on the design of vectors (e.g. immutability, row/column-major, row/column vectors, multiplication) later.
“list” is the name used for an ordered collection of things that can grow (or shrink) dynamically. In some languages, this is called an “array”, but since Dither also have another type that fits the word “array” even better, this one is given the name “list”, which is equally common in other languages to describe such containers. To specify a list, one only needs to provide what type of element it contains, e.g. list[i32].
“arr”, or arrays in Dither are for multi-dimensional fixed-size collection of things. One typical use case for it would be the pixels of an image. Think about it: it needs more than 1 dimension (since you have width and height and maybe channels), but it wouldn't start getting extra pixels randomly in the middle or losing them either. You can of course reshape an array to hold a bigger or enlarged image, but list operations such as insert, remove, push etc. wouldn't make too much sense here. It's also great for things you know wouldn't change size, or you just need to hold a bunch of data bytes. To specify an arr, you give the element type, and the number of dimensions (not number of elements!), e.g. arr[u8,2] is great for a grayscale image. Since the dimensionality is part of the type, you don't get to change that later (and shouldn't need to); Again you can change the actual dimensions dynamically (e.g. resize an image). This container type is included because how often we need to deal with rasters in creative coding, and while using a list for that also works, the benefits of having a separate type justifies so.
“dict” is also known as “map” in some programming languages. But in Dither, the word “dict” (short for dictionary) is picked because there're already too many things called maps. You have the data structure “map”, you have the higher-order function “map”, you have the Processing-style range re-map “map”, if you're writing some game or world you might have a diagrammatic representation of area “map”. So it would be nice to at least have one less “map” to add to the confusion. To specify a dict, you'd write out key and element types as parameters, e.g. dict[str,i32] or dict[vec[f32,2],i32] etc.
“tup” is the tuple type in Dither, e.g. tup[str,i32] or tup[i32,i32,f32,i32]. “union” is the type that can hold one of a given set of types at a moment, e.g. union[str,i32] or union[i32,f32,str].
Booleans
Dither has no booleans. Expressions that should return a boolean returns an i32, where 0 stands for false, and 1 stands for true; The truth value of an expression is defined as whether it is non-zero when cast to an i32. This might seem a bit backwards, but hear me out.
First, you can't really have a variable that just takes up 1 bit. Unless you pack it with other booleans, it'll take a minimal of 8 bits (on modern systems), so there's no real practical gain to declare something as bool instead of int. Secondly, it is very useful to do integer arithmetic on result of boolean operations, e.g. x:=2+(y>3)*4. Granted you can turn it into an if/else statement or ternary expression (and you probably should if the expression is already very complicated), but the former is nevertheless a compact and expressive way to do it. In such situations, some languages forces you to cast explicitly from bool to int, some languages do so implicitly — but why even bother with casting when truth values can just naturally be represented by integers? Thirdly, it allows Dither to have less keywords (bool, true, false), which means less surface area and less mess. Finally, it often happens when one needs to “upgrade” a boolean to hold more states, and having it already be able to hold more than two values can come in handy. (e.g. initially you have a bool for “hide”/“show”, but now you have “hide”/“show”/“show expanded”, which you can assign 0/1/2 and can still test the variable itself for whether anything is shown at all because all non-zero values are true).
Of course this comes with a small cost. For readers of code, it'll be semantically less clear whether an int only stores a bool or a full integer. This can be solved with Hungarian naming. You also don't get to write the words “true” and “false”, but this might actually help with your coding style (instead of writing if (expression == true), just write if (expression)).
The language uses i32 for results of boolean operations (instead of, say, a more compact u8) because it is the natural integer size in Dither (more on that later).
Literals
Determining the data type of literal is important, because Dither is a type-inferred language. So when one declares a variable (of inexplicit type) and assigns it a value, it is the compiler's duty to figure out the type from that value (which can often be a literal).
Numerics
Let's start with numeric literals. The first question is, when one writes x:=42, is it an int or a float? Floats are perhaps more common in creative coding contexts, and arguably more “useful” in general. But, defaulting to int also has a valid case for it, for example, one'd write for (i:=0; i<10; i++) and it'd be silly to have to either specify i:i32=0 each time, or have a float iterator when Dither supports ints. Secondly a 32-bit float cannot actually represent the full range of a 32-bit int (accurately anyways), so to be really fool-proof, it'd be default to a 64-bit float, which does sound a bit too much. Finally, if 42 defaults to a float, then we perhaps need some way of labeling a literal as int, perhaps 42i, which doesn't seem too widely accepted as 42u or 42f.
In the end, Dither went with the less radical way, which meant that x:=42 defaults to x being an i32. To have a float, one would write x:=42.. A single decimal point is hopefully not to tiresome to type. The downside is that people, especially those who came from dynamically-typed languages, might get tripped up initially, declaring an int when they actually need a float. But from personal experience the decimal point becomes muscle memory after writing a couple programs in Dither.
Object Literals
Next comes the question of what to do when initializing container types and objects. We'll start with containers. Some languages have dedicated brackets for each type of container: e.g. [] for an array, () for a tuple, and {} for a dictionary, and so on. The problem with that approach is that you eventually run out of brackets when there're more built-in container types, and will need to label the brackets somehow, or pass an array to a built-in function or constructor to generate value of the actual desired type (e.g. set([1,2,3]), new Map([[1,2],[3,4]])).
Dither decides to allow the use of {} brackets for all initializers, prefixed by the type. For example, to initialize a list, you'd write: list[i32]{1,2,3}. And since Dither is type-inferred, to declare and initialize you'll only need to write out the type once: x := list[i32]{1,2,3} and not x : list[i32] = list[i32]{1,2,3} like in some non-type-inferred language (but you still can if you want).
For objects, you'd write MyType{a:1,b:2} and so on, where you specify fields by name:value pairs. For dictionaries, it works the same: dict[str,i32]{"hi":3,"lo":2}.
This way, Dither does not need extra built-in functions or constructors, and never runs out of brackets. Now the cost is that you'll need to write out the type — which you'll have to do anyways if you declare without initial value. But we're not done yet!
It was determined that some types, such as vectors, are so often used that it'd be quite a pain to write out the type each time in the initializer, e.g. vec[f32,3]{1.,2,3}. If the vector is in a list, then you'd have to do list[vec[f32,2]]{vec[f32,2]{1.,2},vec[f32,2]{3.,4}}, which isn't exactly convenient. Adhering to the math-first approach, Dither decides to give vectors a pass, and does not require the type label in vector initializer. In other words, if an initializer is unlabelled, then it defaults to a vector, e.g. {1.,2,3}. You can still label it to be pedantic, and for other container types you'd label as normal.
Now comes the question whether tuples should get a special pass too. Tuples are mainly for convenience sake (indeed many languages don't have them at all), and it'd be awfully inconvenient, if tuple syntax is, well, inconvenient, which defeats the purpose. Some languages use parentheses () for tuples. This is essentially giving up on comma operators, as the two are mutually exclusive. Comma operator is a quirk-ish syntax where you get to evaluate a bunch of things and keep the last one as value of the whole expression. e.g. a=(b=1,c=2,b+c) will end up in a==3. It seems not that essential nowadays, but I'm somewhat fond of it since it allows you to do all sorts of gymnastics. Some languages replace it with blocks that evaluates to the last expression, but I'm not too sure about whether I want that either. () parentheses are also used for grouping arithmetic expressions, and overloading it this way feels a bit too stealthy, e.g. ((1*(2+3),(4,(5-6)/7))) looks like just some math from afar, but there're some tuples hidden in there.
Regardless of whether or not Dither will end up having comma operators, it seems like a good idea to avoid () for tuples anyways. [] in comparison, seems like a reasonable choice. [] is already used in Dither for parameterization in types, templates, decorators, indexing, etc. These parameters are generally non-homogeneous collection of things, which is similar to the idea of tuples. So in the end [] is picked. The downside is that it seems not a popular choice for tuples in other languages, and it'll perhaps take a bit of getting used to if you came from those languages.
While not in the language right now, some quality-of-life updates are planned for object literals. e.g. figuring out the type parameter from the initializer list automatically, list{1,2,3} instead of list[i32]{1,2,3}, and allowing omission of type label in nested initializers, e.g. list[list[i32]]{{1,2},{3,4}} instead of list[list[i32]]{list[i32]{1,2},list[i32]{3,4}}, etc.
String Literals
There're many decisions to be made with string literals. First, multiline strings. In many languages, a different quote symbol from single line string is used. Some use triple quotes, some use backticks, etc. In some languages there're no special symbol and you'll just be concatenating single line strings. Dither thinks there's no fundamental reason why one can't just have multiline strings by default. In Dither, you just use "abc" for all strings, multiline or not.
Next, string interpolation. It is just so much more convenient than its alternatives, and so essential in programming languages nowadays. Again, seems like there's no reason to invent a special quote syntax for it, e.g. backticks or f" " etc., so in Dither, regular strings " " just supports string interpolation. Now what symbol to use for the actual interpolation? Some languages use ${}, some use \(), some use just {} but those are usually in specially marked strings, otherwise it becomes a bit too Midas-touchy (something that triggers too eagerly).
While the dollar sign $ seems a popular choice, it feels crass to sprinkle money all around, like giving everything a price tag. Dither ends up picking %{} as an aesthetic choice. Now some languages allow you to omit the {} and only have the preceding symbol if you're only embedding a variable, e.g. %name instead of %{name}. Dither rejects this again with the Midas argument.
Control
There're perhaps three major schools of programming languages when it comes to making a block. One uses curly braces {}. One uses English words begin/end or the likes. One simply relies on indentation. It is a most important decision, because it very much affects the overall look and feel of the whole language, and is perhaps the first thing someone notices in the language.
Indentation-based blocks is an interesting approach. It's basically saying “since indenting your code is good practice and everyone should be doing it anyways, why not let that have significance to the parser as well”. While clever at first sight, it feels somewhat fragile. It is a reasonable assumption that a piece of finished/committed code is well-indented, but not so much so for any code in intermediate states, and it is a bit distracting having to constantly dedent/indent parts of the code when one's busy debugging. Also it feels like indentation is more of a convention or style, and forcing meaning on it... I'm not so sure. Not to mention the 2-space v.s. 4-space v.s. tab mess.
There isn't any fundamental issue with begin/end. You have to type a few extra characters, it's a few extra keywords, it makes IDE's life a bit harder, but no biggie. However, there's also no fundamental reason to use it in Dither either. If the programming language tries to give off the look & feel of natural language, or if the language tries to limit the use of symbols (which does improve the flow of keystrokes), then begin/end is a fitting choice. But Dither's design doesn't shy away from symbols and there's just not much incentive to not use the arguably more universal {} blocks.
Now that we've fixed on {}, there's also another choice to make for if/else/for/while statements which prefix blocks. Traditionally, if (predicate) should be followed by a single thing, and {} simply groups together a bunch of things to use as a single thing. Some modern languages realized that, if if (predicate) is always followed by a block, then we can drop the parenthesis around predicate: if predicate {}. This have a few implications. First you'd no longer have those one-liner if statements, like if (x==0) break;, though the number of characters stroke is not much different: if x==0 {break;}. One might even argue it encourages a better coding style (no accidental exclusion of extra statements that should've been in the if body). But there's another subtle catch of dropping () one might not notice: else if. With the traditional approach, else if ... is parsed as else ..., where ... is a single statement, and in this case it is the if ... that follows. So if one writes out the {}, else if is no different from else{if(...){...}}. It is a very clever design, since the compiler doesn't even need to know about the existence of else if, it's just else followed by if; For the programmer, they're essentially getting a very useful “keyword” for free, also without having to realize how it actually works.
By getting rid of the rule that if/else can be followed by a single statement, something special needs to be done to else if. One approach is to invent a new keyword: elseif, elsif or elif. The other approach is just having a keyword that has two words. If the word “else” happens to be followed by the word “if”, then it gets captured as if it's a single keyword.
In any case, it was determined that it's not really worth it to drop the parentheses. Also from aesthetic perspective, being stripped of the parens, the predicate looks a bit “naked”, or it feels like stuff are falling out of a loose bag — I guess both my eyes and fingers are used to having them, and the reason to break from tradition is not strong.
Statements
In many languages, statements are delimited with a symbol, most often the semicolon (;). This proved very inconvenient, as even seasoned programmers forget from time to time. The funny thing is that some compilers will even tell you: “you need a semicolon here”. Well, if you already know that my statement ends here, why can't you just pretend there's a semicolon?
Therefore, many languages simply allows the new line character(s) to serve as statement delimiter. But it feels a bit flimsy though: to derive meaning from whitespace characters (similar argument as blocks-by-indentation). Also there's the problem of a single statement spanning multiple lines: now it becomes a bit annoying to cancel out the newline, with say backslash.
There also exists a third, hybrid approach. Different languages might implement it differently, and here's how Dither handles it: When parsing reaches a new-line character, and if the current statement can be ended without introducing syntax error, the statement is ended; If a semicolon is encountered, the current statement is trivially ended. This approach gives the programmer freedom to decide whether they like to include or omit the semicolons. I personally like using semicolons (hard to say whether it's preference or muscle memory), but when I occasionally forget it when I'm busy fixing some other stuff, I don't want the compiler to start barking at me.
This is of course a compromise between convenience and rigidity. One might also introduce some subtle bugs, such as writing the value to return on the next line of the return keyword, or have a single arithmetic expression that span multiple lines that are also valid as separate expressions, etc. but these are relatively rare and weird way to write code anyways. Since statements are omnipresent in code, the compromise should be worth it, and is arguably best of both worlds.
For Loops
The traditional for loop for(i=0;i<10;++i) often gets challenged. Indeed it is inconvenient in a few respects. Most obviously, you need to type i three times, and it is very easy to make the mistake of writing for(j=0;j<10;i++) and wonder why the loop never terminates (mixing up i and j). Ideally, one would write i only one time. Many languages make this abstraction, and come up with some variation of for (name,start,stop,step). Of course, just plainly laying out these parameters looks a bit confusing (for (i,0,10,1)) and many languages come up some creative new syntax (e.g. for i=0,10,1 do or for i in range(0,10,1) etc.). One downside of these simplifications is that they're much less powerful than the “real” for loop. Let's take a closer look at the latter.
The header of a “real” for loop consists of three things: a statement to be executed before everything, an expression whose truth value will be tested right before each iteration, and a statement to be executed right after each iteration. You can capture some pretty complicated logic in this framework, for instance, having two iterator variables (e.g. for(s=v,t=v+1;t<nv;s++,t++)). One might argue that such complicated things can also be done in the loop body instead, but one might also argue that the purpose of the header of the for loop is to take care of iterators, so initializing, updating and testing of them should logically happen in the header. In any case, it's hard to deny the flexibility of this age-old system. Another example: whether to include the upper limit is simply the difference between i<10 and i<=10. This example also highlights the visual clarity of the syntax: you won't need to tell people in some sort of documentation whether the range is inclusive or exclusive on either ends, (or if a new variable is created for the iterator) — the code is somewhat self-explanatory. It feels like all the current “improvements” to for loop are not conclusive, even though they do have some benefits.
There's another school of argument, which says we can do away with for loops altogether, and use while loops for everything instead. There're problems with that. First, the iterator will need to be initialized outside, and might clash with other loops in the same scope (all called i for example), so the iterator needs to be declared once at the top of each scope and assigned multiple times later — a very old and inconvenient idiom. Moreover, the iterator will need to be updated at the end of the body of the loop, and actual loop body will need to be inserted before the increment, which not only is inconvenient and error-prone, but also makes it hard to see what the increment is at first when we have a longer block. If some new keyword and idiom are introduced, the problems can be alleviated (e.g. {i:=0;while(i<10){defer i++; ...}}), but then why all the trouble?
Therefore, Dither decides to keep the traditional for loop syntax (at least as an option). In the future, perhaps some optional shorthands will be added, e.g. to prevent having to write the iterator thrice, have some sort of token that temporarily represent the iterator within the header scope: for (#i:=0;#<10;#++).
Dither does not include a “for each” loop, because you can use the higher-order map function built into collections, and the benefit of having a separate foreach syntax seems marginal.
While Loops
First question with while loops is whether or not to have them at all. You can express a while loop with a traditional for loop, for (;predicate;){ and for (;;){ (infinite loop), and some languages even go as far as for predicate { and for { by allowing omission of the first and third part altogether. However, it reads a bit awkwardly: “for something is true do something” doesn't make much sense compared to “while something is true do something”. If the programmer wants they can certainly write it that way if it doesn't bother them, but taking while loops away altogether? It seems a bit much. We also have do/while loops and unless we also change it to do/for loops (which is possible, but the sequence of execution will take some explaining), we don't really save a keyword.
Do while loops allows you to execute some piece of code at least once. Without it, you usually need to pick between 3 options: 1. duplicate some code, 2. put code in a function and duplicate the calling code, 3. use an infinite loop and add an if statement to break out. None of these seems too elegant, and there doesn't seem to be an important reason to not have do/while, so it also gets included in Dither.
Switch / Match
Currently Dither does not have switch statements, but the feature might be added in the future. Personally I don't use them all that much, and find else if chains sufficient. But it is also reasonable to want them. If they're to be added, they should also allow type matching and structural matching, in functional programming style. Therefore it won't be trivial to implement, and will need careful planning and design. For now, use if/else if.
Functions
The spelling of keywords if/else/for etc. is pretty much universally acknowledged, but what keyword to use to declare a function? You could, simply have no keyword, and just through arrangement of other symbols have the reader and the parser deduce that some code is in fact function definition. For non-type-inferred languages that put type in front of variable names, the type can sort of serve as the “function” keyword (but you'll have to read on to distinguish between variable and function declaration). For those languages that do have a keyword, choices vary between various spellings of “function”, e.g. fn, fun, func, funct, function, or some various spellings of synonyms of “function”, proc, procedure, sub, subroutine, or focus on the action of “defining” a function, def, define, or a mash between the two, defun, letfn, or even just prepositions such as to and on.
Ideally the keyword should not be too short (or non-existent), because then there wouldn't be enough visual pattern to latch onto when reading code (see core ideas above). It should also not be too long, lest typing and reading become tedious.
The frequency of occurrence of a keyword should also be taken into account. If a keyword is going to be everywhere, it'd better be very short. If it only occurs a few times in a program, then it doesn't hurt to have a longer word.
When the rule is applied to the function keyword, it would make sense for functional programming languages to have a very short keyword, and fn and fun would make sense. Dither is not a functional programming language; Dither embraces a lot of functional ideas (e.g. functions are values). Therefore, again, Dither should have a function keyword that is neither too long nor too short.
“Subroutine”, “procedure” and their abbreviations aren't super fitting, as they lean in the opposite direction of functional programming, which Dither does not.
Taking all the above into account, func seems to be a solid choice. The full version of “function”, due to the layout of most keyboards, is very easily misspelled as funciton (or some other variations). fun and funct are competitive choices in terms of length, but fun is also another English word, and feels a bit, well, funny when used to mean “function”. funct is on the longer side and is not so widely seen nowadays. That leaves us with func.
Lambda Functions
You can create unnamed functions in Dither by, well, omitting the name in a function declaration. In this case, the function becomes a value that can be passed into other functions, or assigned to variables. e.g. f := func(x:f32):f32{return x*2} instead of func f(x:f32):f32{return x*2}.
Now many programming languages introduce an alternative, shorthand syntax for simple, unnamed functions, sometimes referred to as lambda functions. One one hand, you occasionally save some keystrokes; on the other hand, new operators and syntax (and code to parse and compile them) will need to be introduced. There'll also be subtle gotchas that either need explaining or banning. In comparison, the current form of unnamed functions in Dither is pretty clear, and doesn't have some sort of error-prone redundancy that needs fixing. Therefore, while some shorthand might be added in the future, one should stick to the standard form for now.
Classes / Structs
Structs are quite useful in programming languages as they allow you to group nonhomogeneous things together and label them. They're not absolutely required, but complex things will become very messy if we don't have them. It is a very powerful thing to add though, because it gives the programmer the power to create types. We were able to create a bunch of values of built-in types, or even play lego with the built-in types given the parametric type system, but now, we get to create our own types.
The next question is, whether structs should stay as structs (or records, or POD, or whatever you call them), or should we embrace object-oriented programming (OOP). It was decided that while an object is a suitable abstraction some of the times, the full set of ideals of OOP (e.g. encapsulation, hiding, inheritance) does not align with those of Dither.
Therefore, Dither's object orientation stops at being able to add methods to a struct, and the methods get the object itself passed implicitly (this/self). There's no inheritance, no subclass, friend class, super, private, public, protected, getters, setters, constructors, virtual and all that. These additional constructs distract the programmer from directly understanding and solving the problem at hand, and make them waste effort on building up this sort of over-packaged, bloated, generic hierarchical structure. Granted, OOP can set up a framework for mediocre programmers to not mess up too much in a big team, but as stated in the core ideas, this is not the goal of Dither.
Being able to add methods to a struct is not a bad idea though, since it adds scope to the functions, and gives a cleaner and more familiar syntax (a.b(c) instead of b(a,c)). In this spirit, uniform function call syntax (UFCS) is also supported in Dither, so any function which takes a struct as first argument, can be called as if it is a method of the struct. UFCS doesn't completely replace the need for methods, as it gives more limited naming and scoping options.
Usually, programming languages reserve a special variable name for methods to refer to the object it is attached to. There're roughly three schools: 1. A reserved name such as this or self. 2. Refer to fields of the current object directly (e.g. just a instead of this.a if a is a field). 3. Making you write out the name of self-reference yourself (def method(self,...):).
The third option is obviously inconvenient, and defeats half the purpose of having a method instead of a function, while introducing new potential for bugs (e.g. forgetting to specify it). Those that go with the second option often also allow the first option to disambiguate in ambiguous situations. Nevertheless, it can be somewhat confusing, not being able to tell fields from other variables. The first option is the safest choice, albeit a verbose one. You'll end up writing this.a = (this.b-this.c)+this.d and so on, which is not very convenient.
Therefore, Dither introduces a fourth approach, which is to allow the use of . as a shorthand to this.. So you can write .a = (.b-.c)+.d instead. This way one can clearly tell between fields and other variables without having to type too much. For those who enjoy typing, this. can still be used in Dither (but option 2, i.e. not having anything, is not allowed). The keyword this is picked in favor of self as the latter is prone to be mis-typed as slef on most keyboards layouts.
Now comes another naming question: what to call the keyword that lets you create a new struct? struct seems like an obvious choice (with class being too OOP-sounding). However, Dither also wants to reuse the keyword for making type aliases, and (in the future) for algebraic data types. type was also considered, but it felt like it could refer to just a type, and the need to do so might arise in the future, so we don't use up the word so rashly. typedef was picked in the end, as it is already familiar to many, and clearly states that we're defining a type, whether from scratch or from other types. Therefore to define a struct, one would write typedef X = { a:=1; b:=2; }, to alias, typedef X = Y; and (in the future, exact syntax detail to be figured out) to do algebra with types: typedef X = Y | Z;.
Intrinsics
The built-in types (str, list, arr, ...) require functions or methods that operate on them for them to be useful at all, take list for example, one would at least need insert, remove, length and so on. One approach which some languages adopt is to have all these built into the language itself. However, that would bloat up the language and it'll need to be constantly updated if more functions are needed (slice, map, foreach, the list could grow). Some languages' solution is to have as few built-in types as possible to keep things minimal. Other languages exclude these container types entirely from the language and implement them in standard library. Among these languages, the programmer are either given very high privilege, being able to overload all kinds of operators, or be forced to bear with lots of inconvenience.
None of these ideas aligns too well with Dither, so Dither took a hybrid approach. All the built-in types are part of the language, but methods and functions that operate on them are written in the standard library. In other words, one can declare, initialize, index and use some basic features of the built-in types (e.g. arithmetic on vec), but the more advanced features requires including the corresponding stdlib (e.g. include "std/vec" to use v.mag()). The benefit of this approach is that the language itself stays relatively small, and doesn't have to know all the crazy features that might later be added to the built-in types, while the standard library handles all the complex stuff and can grow as Dither matures. Additionally, the language and standard library can be implemented separately by different people. Though the user will now have to type include "std/...", I think it's not a bad idea to be explicit and be modular, and there's always include "std/core" that imports all the built-in type methods at once for the lazy.
Of course, a little bit of magic has to be sprinkled in for such a hybrid approach. The standard library codes that implements the types get a special treatment, so the programmer can get a sweeter syntax that makes it feel like they're using built-in methods. In the future, new keywords might be introduced so this exception doesn't have to be made, and users can write their own extension of internal and external types.
Another exception has to be made for vec.map, which is a higher-order function on the built-in vec type. It has to be implemented as part of the language instead of the standard library. If you think about it: vectors are immutable, so you can't have a loop changing or adding one element at a time; and the dimension of the vector is not known beforehand. You could theoretically generate a one-hot vector for each dimension and sum it up, but then 1. it'd be awfully inefficient and 2. you'll now need a function to generate a one-hot vector, which also isn't covered by Dither's syntax. Therefore, when you write .map on a vector, it gets captured preemptively by the compiler which flattens it into a bunch of instructions, and the standard library will never need to hear of it.
Math
Dither adopts the widely accepted symbols in programming languages for mathematical operators, such as + for addition, - for subtraction, *, / and so on. ** is used to raise a number (or vector) to a power (^ is for XOR). Operator precedence is also as one would expect. This ensures that programmers will have least surprise coming from other languages.
For matrix multiplication, Dither coins the operator @*. The * part is reminiscent of the regular multiply, and the @ symbol, otherwise unused in math operators, is picked to prefix it. @ itself is already used in some languages and libraries to mean matrix multiplication, so this is not only a aesthetical and practical choice, but also in the hope that programmers find it familiar. When the regular * is used on vectors and matrices, it means element-wise multiplication (Hadamard product).
Additionally, Dither introduces a pair of new operators. The following pattern appears a lot when doing geometry-related math: xmax = max(xmax,x), which is sometimes followed by xmin = min(xmin,x) and ymax = max(ymax,y) and so on. This is rather verbose and error-prone, as one has multiple opportunities to mix-up one of ax/in and x/y on each line. The new operators solve this issue by allowing one to write each identifier only once. To find the max of two numbers and assign it to one, one would write xmax >?= x and for the min, xmin <?= x. The operators can be read out aloud as “max equals” and “min equals”.
Vectors & Matrices
As previously explained, vectors and matrices are regarded as first-class citizens in the language. Many design choices had to be made, however.
Row- v.s. Column-major
Mathematicians are probably more familiar with the row-major form. However, those languages and frameworks that work with column-major also have their points. Consider a vector, typed out in your program in the plainest way: {1,2,3}. Is this a row-vector or a column-vector? Now, if you compose a matrix using three of such vectors, then your matrix will naturally be row-major if you used row-vectors, and column-major if you used column-vectors. But here comes the problem: if you're using vectors to represent points and directions in 2D/3D space, and are using matrices to represent transformation (which covers a large percentage of cases where vectors/matrices are needed in creative coding), then defaulting to column vectors is suddenly a lot more appealing. This is because to apply a transformation to a point, we usually left-multiply a matrix to a column-vector holding the point. This is perhaps why some languages use column-major/column-vectors. Of course, you can just be a heretic and right-multiply a matrix to a row-vector to the same effect, but that's probably just too heretical.
But there's also the visual aspect: unless you write your vectors with a newline inserted after every component, it is going to look like a row-vector, since the natural writing direction in most code editors are left-to-right. When you write out a matrix, whether it is composed of a vector on each line, or just numbers arranged in a grid, it is going to look like a row-major matrix. It'll be awkward to recognize them otherwise.
So on one side we have mathematicians and code editors, and on the other side we have a very practical use case. But let's look at that use case closely again. On the left hand side of the matrix multiplication, we have a NxN matrix, let's just say it is 4(row)x4(col). On the right hand side, we have a Nx1 vector, say 4(row)x1(col). By the rule of matrix multiplication, the number of cols on the left(4) must equal the number of rows on the right(4), and the result will have the number of rows(4) of the left and the number of cols of the right(1). Now if we have a row-vector(1x4) on the right, then the multiplication will be invalid — mismatched dimensions! Therefore, Dither makes use of the fact that there's only one type of vector (either row or column) that'll be valid in a matrix-vector multiplication scenario. Here's how it works:
The most commonly used 1D vec (i.e. order/rank/degree-1) in Dither, by default, is neither row-major nor column-major. Its type has only 1 dimension parameter: vec[f32,4]. A row-major vector, like a matrix, has 2 dimension parameters in its type: vec[f32,4,1], and similarly for a column-vector: vec[f32,1,4]. Usually when an operation that requires 2 dimensions is given a 1D vector as operand, the 1D vector is automatically promoted to a row-vector, by appending another dimension parameter 1 at the end: vec[f32,4] -> vec[f32,4,1] (or even vec[f32,4,1,1,1,....] when more dimensions are required). In this sense, you can say Dither vectors are by default row vectors. However, when matrix multiplication has a 1D vector as an operand, whether it gets promoted to row- or column- major depends on the correct shape needed at that particular position. In other words, you don't need to worry about it — and when you do, you can always be explicit about it.
In this system, matrices are naturally row-major (higher dimension is written first in the type). Therefore, you can directly copy formulae you read from textbooks into Dither, you won't need to twist your head 90 degrees whenever you write out elements of a matrix, and you won't need to transpose your vectors whenever you want to apply a transformation to it.
Literals
As we covered before, one can write out a vector literal by either making use of the type-prefixed initializer syntax vec[f32,4]{1,2,3,4} or omitting it {1.,2,3,4}. However, what's to be done with higher dimensions? Of course, we could force the user to prefix with the type: vec[f32,2,2]{1,2,3,4}, and the contents of {} will be parsed according to the shape requested. However, there seems to be many opportunities for a better shorthand. Some languages would nest the curly braces: {{1.,2},{3.,4}}, but that would imply it is composed of vecs of lower dimensions, which isn't the metaphor suggested by the type notation (vec[f32,2,2] is not really vec[vec[f32,2],2]). The nesting {} can also look (slightly) messy. Therefore, Dither sides with those languages that use semicolons ; to delimit rows of a matrix — you can use {1.,2,3; 4,5,6; 7,8,9} to mean a 3x3 matrix in Dither without any additional annotation. For tensors of higher orders, one would have to write out type prefix, as these are in comparison rarer.
Namespaces
In some programming languages, files create namespaces. This is bad. In some languages, files and namespaces create namespaces. This is better. In Dither, namespaces create namespaces; files create nothing. Relying on files and folders has a tendency to tempt people into making lots of them, nested and with little content inside; Manually specifying namespaces is flatter, clearer and more intentional.
In Dither, you can use the namespace X {...} keyword to create a namespace named X with the content inside the {}. To access members of the namespace, use a single ., e.g. X.abc.
When a file is included in Dither, it is first checked whether the file has already been included or not. If it is the latter case, the entirety of the file is parsed and inserted into the current source. While this approach might seem a bit antiquated, it has the benefit of being direct, straightforward and versatile — in the included file, you can put its content into a namespace (or multiple namespaces), and modularity is in the control of the programmer. Dither does not force a folder structure on you.
Exploding a namespace so that everything in it pollute the globals is currently not supported. Therefore, it is recommended that libraries pick short, simple names for their namespaces, and indeed it is what's been done with the standard libraries. Whether Dither will support explosive features in the future is undecided, but it seems not a bad idea to force everything to be scoped at all times to avoid ambiguity and maintain clarity (relieves readers from the constant question “where did that come from?”), at the price of some keystrokes.
Embed
One of the initial goals of Dither, is to unify GPU code (shaders) and CPU code: You only need to learn one language (Dither). In a program the same helper function can be reused in both CPU code and GPU code. You only write once.
But the question is how would the syntax work? Normally the compiler just translate the entire Dither program into bytecode; We need some way of marking pieces of Dither code that should be also translated to shader language. This ideally should happen at the language level and not library level — otherwise each library will need to re-implement parsing of Dither, and will also need to have access to user's original source code (when everything else is down to bytecode / machine code).
Since Dither doesn't really believe in built-in functions (things are either keyword or stdlib), it seems apparent that a new keyword is needed, and it should go like this: <keyword> <pointer-to-some-code>. One might even suggest makeshader "path/to/shader.dh". However, it should be immediately apparent to any ambitious language designer that this feature should not be limited to just making shaders, instead it ought to mark the beginning of a very powerful macro / plugin system. Therefore, the syntax is settled: embed <something> as "fragment". And the code-generator for fragment shaders is hooked onto the Dither compiler registering by the name "fragment", while other plugins will be registered by other names. The compiler, when encountering an embed statement, finds the appropriate plugin and passes off some abstract syntax tree (AST) to the plugin, which in turn churns out some artifact which the compiler resumes with.
But some details are yet to be decided. What is <something>? It could be path to a file. But that would contradict Dither's philosophy that files mean nothing (see section above), and the programmer will unnecessarily create many separate files, which make code-reuse between CPU and GPU a messy business to organize. Therefore, since we already have the AST ready at this stage, why not just let user specify an entry point function? The compiler intelligently figures out all the global variables and helper functions recursively referred to by the entry function, extracts them, and kicks them off to the plugin.
Currently, Dither allows the plugin to return a string. Therefore, for the fragment shader example, one would write shader := frag.program( embed myfun as "fragment") with frag.program being the standard library function to compile a shader from a string. It is as if the user wrote the shader code themselves between the parenthesis shader := frag.program("..."). One can also make use of Dither's nameless function syntax, to directly write the function within the embed statement. In the future, Dither will probably support plugins that return more than a string, perhaps a new syntax tree.
Dither will officially provide a few plugins (currently just fragment shaders, next-in-line a certain assembly code that runs in browsers), and users can write their own: they can contribute if they like, or just use locally by telling their copy of Dither compiler where to find the plugin.
As you might have noticed, hopefully, the embed statement makes a very powerful and versatile macro system. Instead of only writing libraries, you write languages within a language.
Hints
As the embed statement was being developed, it gradually became clear that some sort of way to mark up an extension of Dither syntax might be necessary, because some syntax in the language that the plugin targets might not have an exact Dither counterpart. For example, in shaders, some variables are built-in, some are passed between stages, some are external parameters, and shading languages often have a way of distinguishing between them. While there are alternative solutions (such as giving things special names or prefixes, or packing them up in custom structs, which might even better mirror the way some shading languages work), none of them seemed too convenient or consistent with Dither's design.
Therefore, after much thought, Dither introduced a non-intrusive way to mark up code for plugins. I call them “hints” — they're otherwise completely ignored by the Dither compiler, but could be meaningful for certain plugins. For the shader example, one would write @uniform myparam : f32 in the arguments to the entry function to mark it as a uniform, the same goes for @varying, @builtin, etc.. The syntax is more formally defined as @ <something> <something>, with @ being a prefix operator, and the space between it and the first operand optional and usually omitted for aesthetical reasons. Because @ has high precedence, to mark more than a single token, one would need a pair of parentheses: @<something> (<some-expression>), e.g. @myhint(1+1). We're not done yet! The first <something> can also be an expression, and since subscript operator [] has higher precedence than @, you could write @myhint[param1,param2] (1+1), as a way to pass parameters to the plugin. The Dither compiler of course just sees (1+1). In the AST, the first operand gets stored as an optional attribute of the second operand.
Imagine the possibilities! Parameter/GUI can perhaps be built with @range[0,2] x := 1, accelerated math can perhaps be marked with @simd(x + y), and strict syntax checkers can perhaps check for @const x := 1 and @pragma "strict" or whatever.
Libraries
The functionalities of Dither language are supplemented by libraries. A library can be just a single file, or a folder of files. It can be written purely in Dither, or consist of a Dither wrapper and a collection of implementations for each compile target Dither supports. When you write include "path/lib", Dither intelligently figures out which sort of library you have, and imports it accordingly.
The libraries that come for “free” with an installation of Dither language are called the standard libraries.
Standard Libraries
Dither offers a whole suite of standard libraries encompassing most of the things you may possibly want as a creative coder. This long document will yet double its length if the design of each standard library is recounted in detail. Therefore, this section will only cover the guiding principles and design decisions these libraries share in common.
The standard libraries try to use system-native API's as much as possible. While in theory if we're lazy, we can just wrap third-party cross-platform libraries, the bloat and overhead will be incurred on our users, and that'll be uncool. Therefore, many of the libraries are painstakingly rewritten for each OS — I suffer so you won't have to suffer.
Additionally, the user has the freedom to select a backend for a library if multiple backends are available in their OS/environment. Therefore, the standard library API's are designed to be generic, and are not specific to a certain backend. In other programming languages, there're often libraries that are explicitly wrappers of certain technology — Dither's std tries to avoid that, since technology can easily be deprecated, and the API's should focus on the task or problem on hand itself; Also, the users shouldn't have to worry about some quirks or details of the actual backend. That said, one can totally write a library for Dither that focuses on a specific OS and a wraps a specific technology, and that could very well be a useful tool and welcome contribution to the Dither community, but the standard libraries that comes with Dither should stay generic and stay agnostic.
The standard libraries often provide somewhere between a low- and a high-level abstraction. On one hand, it saves you all the tedious setting-up from zero to something, and hides the nasty bits behind a nice friendly API; On the other hand it doesn't assume much about what you're doing, and you'll still build up whatever you need with a somewhat low-level mindset. I believe this should be the way with any standard library of a programming language: it either enables you to do something that you can't possibly do with the language alone, or implements some feature that is so ubiquitously needed that it'd be a pain to not have. But it shouldn't force you into some abstract model that fits certain popular applications — that should be the responsibility of a custom third-party library that builds on top of a standard library.
Dither's standard library sticks to the built-in dataypes as much as possible. If a function is to return a bunch of things, it'll probably be in a list[thing]. If a function deals with pixels, you can probably give it an arr[u8,3]. They actively steer away from creating “opaque” types like ThingCollection or ImageData. This reduces friction between different libraries and your code, and makes how to use these functions more immediately obvious.
Conclusion
Thanks for reading thus far — hopefully this document gives a rough idea of why things are the way they are in Dither. Dither does not try to please everyone with every design decision — it would be a fool's errand, as anyone who has an opinion probably has their own reasonable justification.
Instead, I focus on what I think would be a good model based on my experience with existing programming languages, programmers of various skill levels I encountered online or in real life, and creative coding in general. I want to create something that I think is good and I want to use, in the hope that others might find it good also. I think perhaps the most important principle of a design is to be (mostly) consistent with the principles: to not contradict one self, except for necessary reasons. In that regard, any and all criticisms are welcome, if they help make Dither more consistent with its core ideas.
If you find these ideas generally agreeable and align with those of your own for the most part, then feel free to give Dither a try! If you find them appalling and do not align with those of your own, please feel free to also give Dither a try. It might grow on you — or at least, you will be able to illustrate your denouncement of Dither with code examples!